Behind the Scenes: Density Fields for Single View Reconstruction
CVPR 2023| Felix Wimbauer1,2 | Nan Yang1 | Christian Rupprecht3 | Daniel Cremers1,2,3 |
| 1Technical University of Munich | 2MCML | 3University of Oxford |
Abstract
Inferring a meaningful geometric scene representation from a single image is a fundamental problem in computer vision. Approaches based on traditional depth map prediction can only reason about areas that are visible in the image. Currently, neural radiance fields (NeRFs) can capture true 3D including color but are too complex to be generated from a single image. As an alternative, we introduce a neural network that predicts an implicit density field from a single image. It maps every location in the frustum of the image to volumetric density. Our network can be trained through self-supervision from only video data. By not storing color in the implicit volume, but directly sampling color from the available views during training, our scene representation becomes significantly less complex compared to NeRFs, and we can train neural networks to predict it. Thus, we can apply volume rendering to perform both depth prediction and novel view synthesis. In our experiments, we show that our method is able to predict meaningful geometry for regions that are occluded in the input image. Additionally, we demonstrate the potential of our approach on three datasets for depth prediction and novel-view synthesis.
Overview
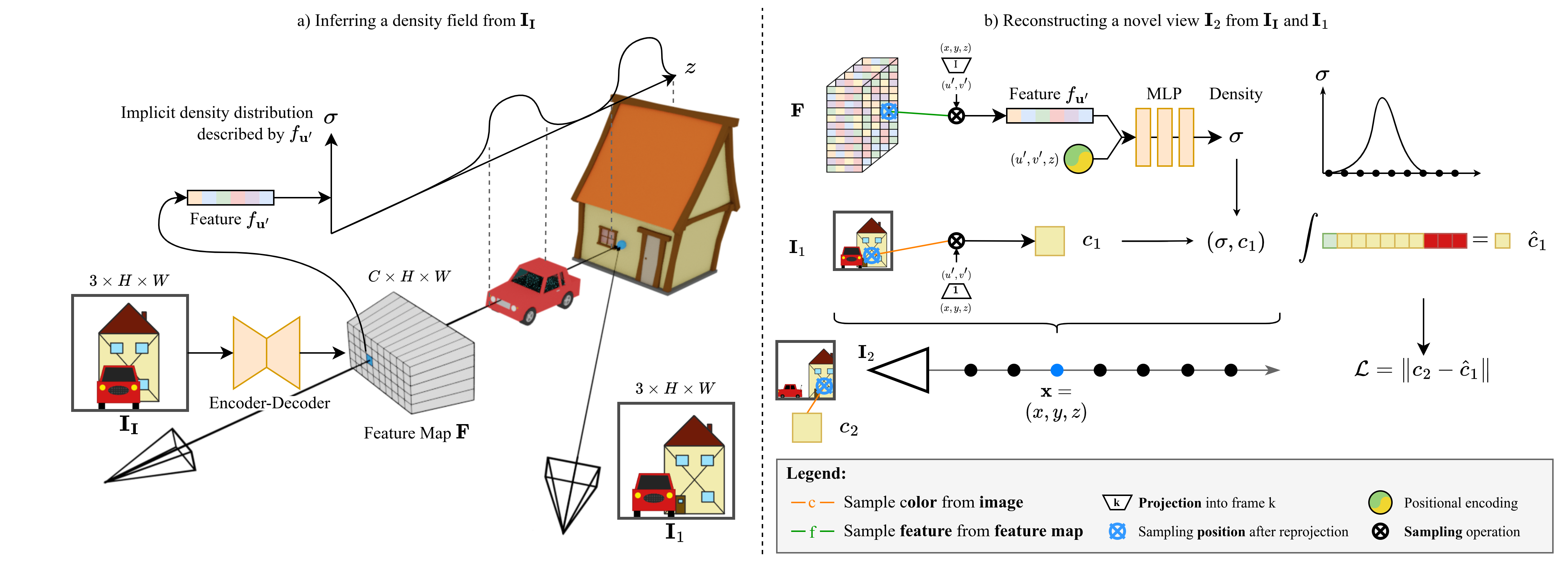
a) Our method first predicts a pixel-aligned feature map F, which describes a density field, from the input image II. For every pixel u’, the feature fu’ implicitly describes the density distribution along the ray from the camera origin through u’. Crucially, this distribution can model density even in occluded regions (e.g. the house).
b) To render novel views, we perform volume rendering. For any point x, we project x into F and sample fu’. This feature is combined with positional encoding and fed into an MLP to obtain density σ. We obtain the color c by projecting x into one of the views, in this case I1, and directly sampling the image.
Learning True 3D
Similarly to radiance fields and self-supervised depth prediction methods, we rely on an image reconstruction loss. During training, we have the input frame II and several additional views N = {I1, I2, …, In}. For every sample, we first predict F from II and randomly partition all frames N̂ = {II} ∪ N into two sets Nloss, Nrender. We reconstruct the frames in Nloss by sampling color from Nrender using the camera poses and the predicted densities. The photometric consistency between the reconstructed frames and the frames in Nloss serves as the supervision signal of the density field.

The key difference to self-supervised depth prediction methods, is that by design depth prediction methods can only densely reconstruct the input image. In contrast, our density field formulation allows us to reconstruct any frame from any other frame. Consider an area of the scene, which is occluded in the input II, but visible in two other frames Ik , I1k+1, as depicted in the figure. During training, we aim to reconstruct this area in Ik. The reconstruction based on colors sampled from Ik+1 will give a clear training signal to correctly predict the geometric structure of this area, even though it is occluded in II. Note, that in order to learn geometry about occluded areas, we require at least two additional views besides the input during training, i.e. to look behind the scenes.
Results
Occupancy Estimation
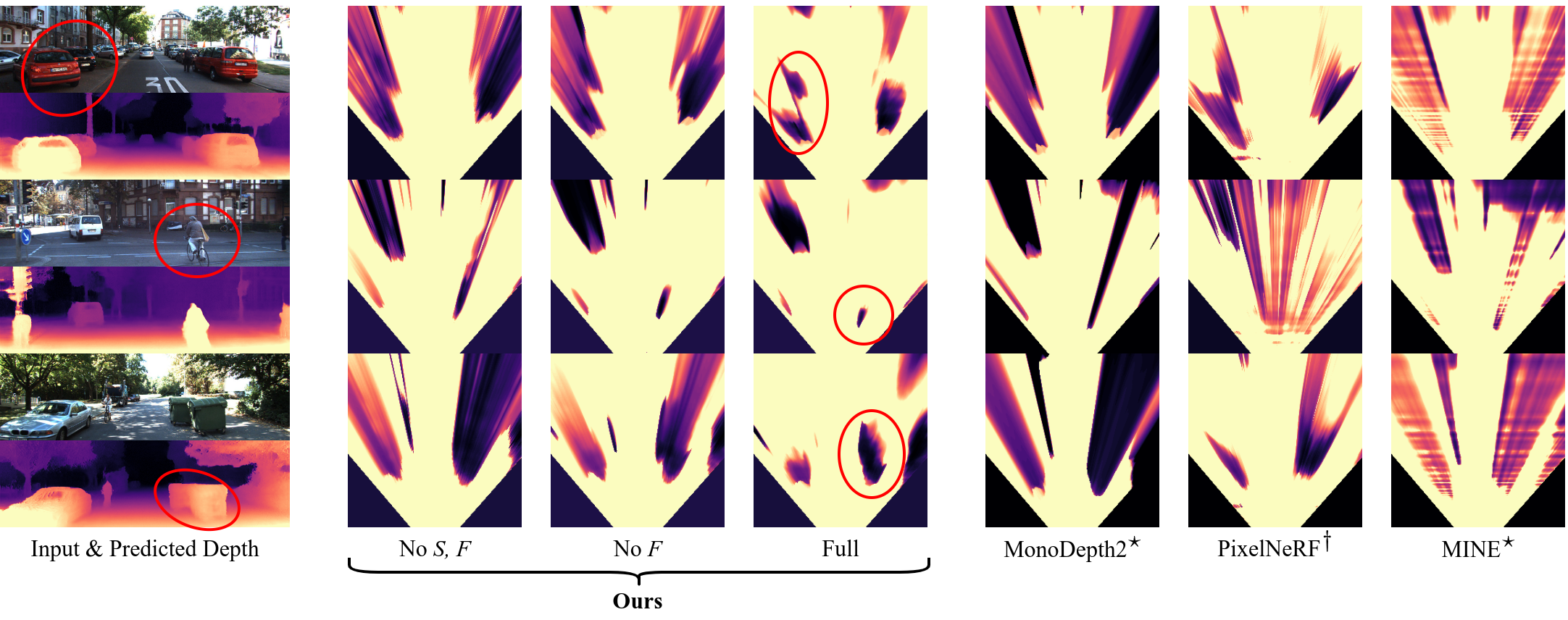 Top-down visualization of the occupancy map predicted by different methods.
We show an area of x = [−15m, 15m], z = [5m, 30m] and aggregate density from the y-coordinate of the camera 1m downward.
Depth prediction methods such as MonoDepth2 do not predict a full 3D volume.
Thus, objects cast “occupancy shadows” behind them.
Our method predicts the full occupancy volume and can thus reason about the space behind objects.
Training with more views improves occupancy estimation.
Inference is from a single image.
Legend: n T(): n timesteps of, L: left camera, R: right camera, F: left and right fisheye camera.
Top-down visualization of the occupancy map predicted by different methods.
We show an area of x = [−15m, 15m], z = [5m, 30m] and aggregate density from the y-coordinate of the camera 1m downward.
Depth prediction methods such as MonoDepth2 do not predict a full 3D volume.
Thus, objects cast “occupancy shadows” behind them.
Our method predicts the full occupancy volume and can thus reason about the space behind objects.
Training with more views improves occupancy estimation.
Inference is from a single image.
Legend: n T(): n timesteps of, L: left camera, R: right camera, F: left and right fisheye camera.
Top-down visualization and expected ray termination depth for entire sequence.
We use similar parameters as mentioned above. The shown sequence is 2013_05_28_drive_0000.
Smooth transition from expected ray termination depth to novel view synthesis to birds-eye occupancy.
We use similar parameters as mentioned above. The shown sequence is 2013_05_28_drive_0002.
| Model | Oacc | IEacc | IErec |
|---|---|---|---|
| Depth | 0.95 | n/a | n/a |
| Depth + 4m | 0.92 | 0.64 | 0.23 |
| PixelNeRF | 0.93 | 0.64 | 0.41 |
| Ours (No S, F) | 0.93 | 0.69 | 0.10 |
| Ours (No F) | 0.94 | 0.73 | 0.16 |
| Ours | 0.95 | 0.82 | 0.47 |
3D Scene Occupancy Accuracy. We evaluate the capability of the model to predict occupancy behind objects in the image. Depth prediction naturally has no ability to predict behind occlusions, while our method improves when training with more views. Inference from a single image. Samples are evenly spaced in a cuboid w = [−4m, 4m], h = [−1m, 0m], d = [3m, 20m] relative to the camera. We use the same models as in the previous figure.
Depth Prediction
| Model | Split | Abs Rel | Sq Rel | RMSE | RMSE Log | α < 1.25 | α < 1.25² | α < 1.25³ |
|---|---|---|---|---|---|---|---|---|
| PixelNeRF | Eigen | 0.130 | 1.241 | 5.134 | 0.220 | 0.845 | 0.943 | 0.974 |
| EPC++ | 0.128 | 1.132 | 5.585 | 0.209 | 0.831 | 0.945 | 0.979 | |
| Monodepth2 | 0.106 | 0.818 | 4.750 | 0.196 | 0.874 | 0.957 | 0.975 | |
| PackNet (no stereo) | 0.111 | 0.785 | 4.601 | 0.189 | 0.878 | 0.960 | 0.982 | |
| DepthHint | 0.105 | 0.769 | 4.627 | 0.189 | 0.875 | 0.959 | 0.982 | |
| FeatDepth | 0.099 | 0.697 | 4.427 | 0.184 | 0.889 | 0.963 | 0.982 | |
| DevNet | 0.095 | 0.671 | 4.365 | 0.174 | 0.895 | 0.970 | 0.988 | |
| Ours | 0.102 | 0.751 | 4.407 | 0.188 | 0.882 | 0.961 | 0.982 | |
| MINE | Tulsiani | 0.137 | 1.993 | 6.592 | 0.250 | 0.839 | 0.940 | 0.971 |
| Ours | 0.132 | 1.936 | 6.104 | 0.235 | 0.873 | 0.951 | 0.974 |
Depth Prediction. While our goal is fully volumetric scene understanding, we compare to the state of the art in depth estimation trained only with reconstruction losses. Our approach achieves competitive performance with specialized methods while improving over the only other fully volumetric approach MINE. DevNet performs better, but does not show any results from the volume directly.
Novel View Synthesis
Novel-view synthesis on KITTI. We only use a single input frame, from which we both predict density and sample color. This means, that areas that are occluded in the input image do not have valid color samples.
Novel-view synthesis on RealEstate10K. We only use a single input frame, from which we both predict density and sample color. This means, that areas that are occluded in the input image do not have valid color samples.
Citation
@article{wimbauer2023behind,
title={Behind the Scenes: Density Fields for Single View Reconstruction},
author={Wimbauer, Felix and Yang, Nan and Rupprecht, Christian and Cremers, Daniel},
journal={arXiv preprint arXiv:2301.07668},
year={2023}
}
Acknowledgements
This work was supported by the ERC Advanced Grant SIMULACRON, by the Munich Center for Machine Learning and by the EPSRC Programme Grant VisualAI EP/T028572/1. C. R. is supported by VisualAI EP/T028572/1 and ERC-UNION-CoG-101001212.