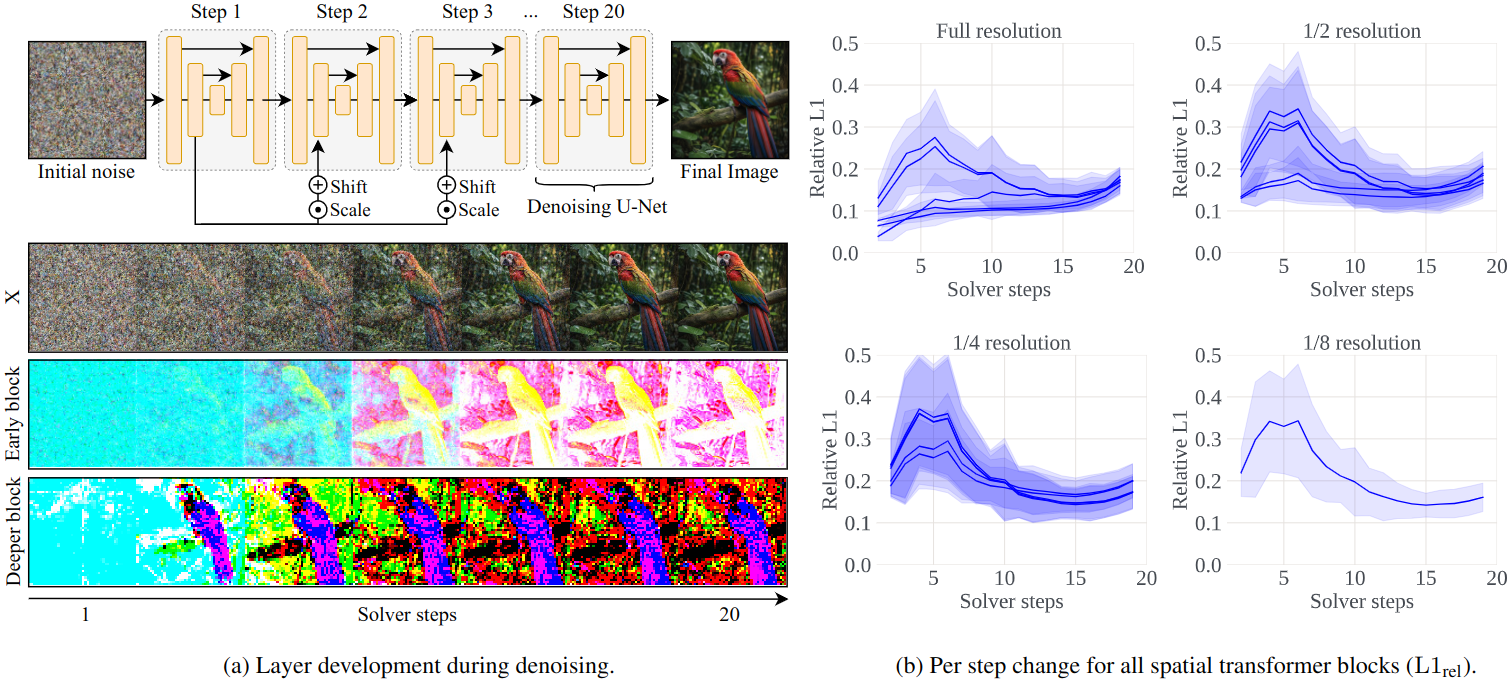
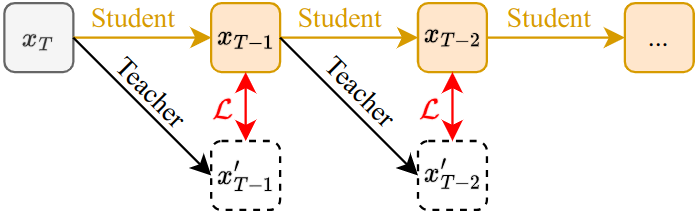
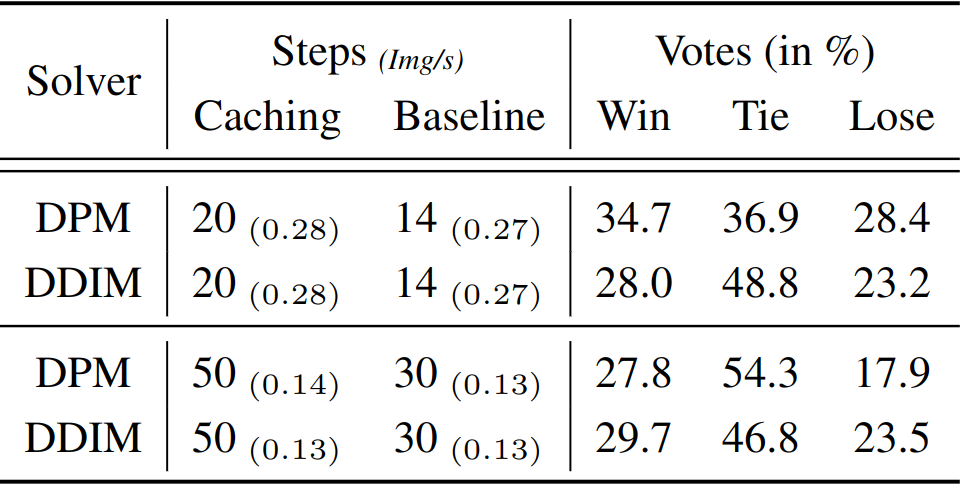
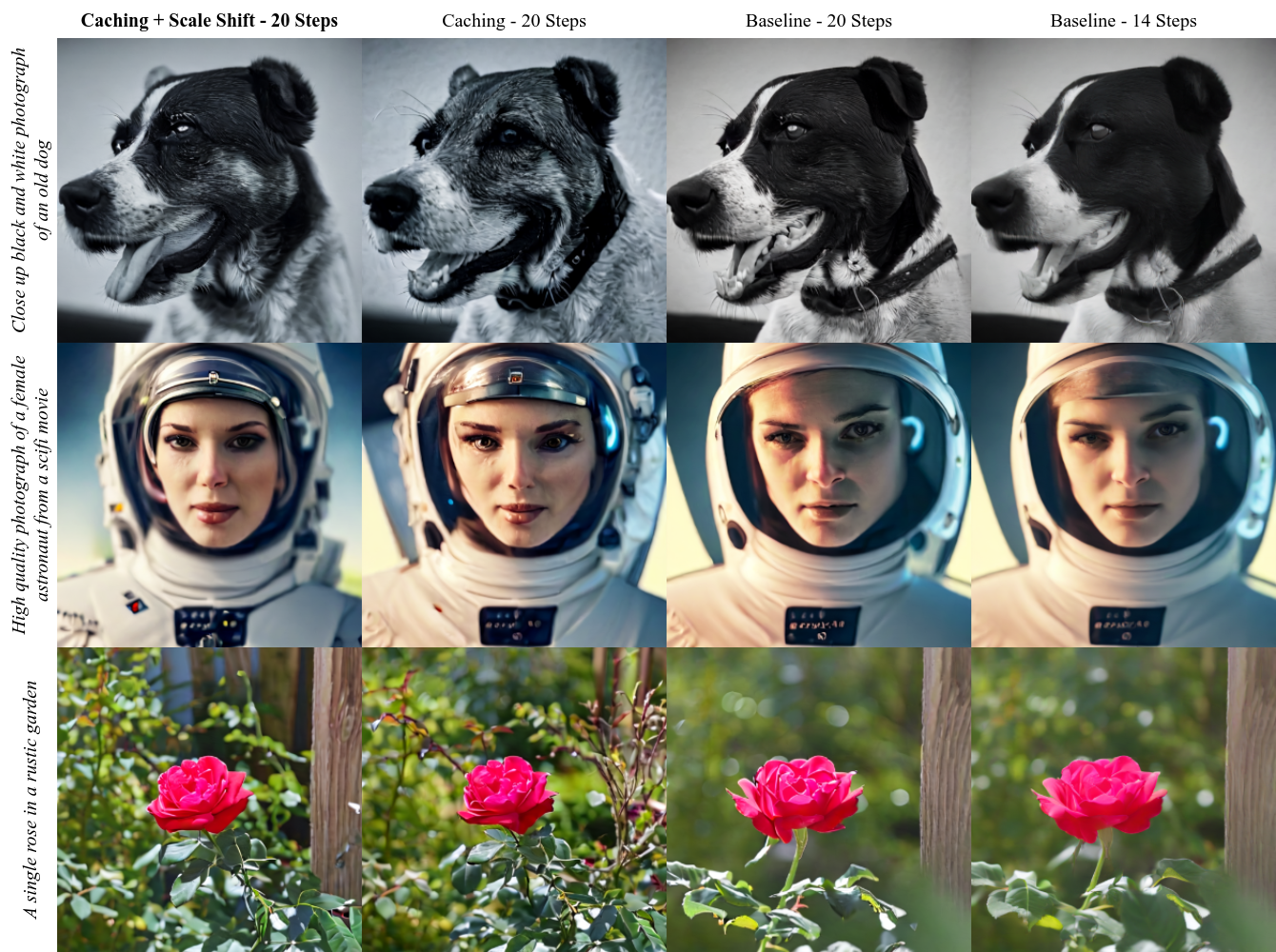
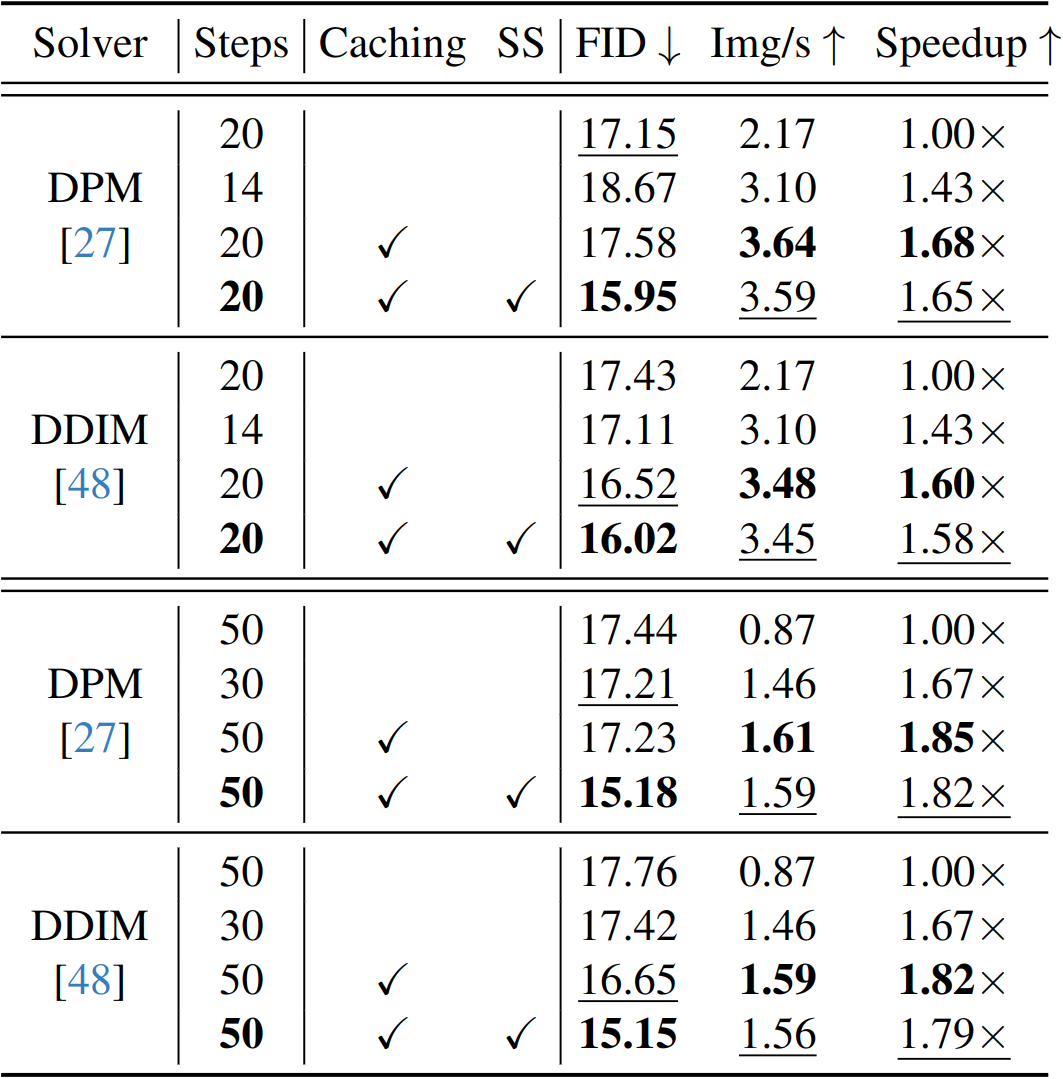
Speeding up diffusion models through block caching. We observe that there are many redundant layer computations at different timesteps in diffusion models when generating an image. Our block caching technique allows us to avoid these unnecessary computations, therefore speeding up inference by a factor of 1.5x-1.8x while maintaining image quality. Compared to the standard practice of naively reducing the number of denoising steps to match our inference speed, our approach produces more detailed and vibrant results.