|
Felix Wimbauer
I am a third-year ELLIS PhD student at the Computer Vision
Group co-supervised by Prof. Daniel Cremers
(Technical University of Munich) and Prof. Christian Rupprecht (VGG, University of Oxford).
Email / Scholar / LinkedIn / Twitter / Github / Group Website |

|
UpdatesJune 2025 I started a Student Researcher position in Federico Tombari's group at Google Zurich on generative 3D. June 2025 Three papers, Back-on-Track, Dream-to-Recon, and SceneDINO, were accepted at ICCV 2025. February 2025 AnyCam was accepted at CVPR 2025. February 2024 Cache Me if You Can, alongside ControlRoom3D and Multiview Behind the Scenes were accepted at CVPR 2024. December 2023 I completed my internship at Meta and the resulting paper Cache Me if You Can is out on ArXiv. October 2023 Our work S4C on self-supervised semantic scene completion was accepted to 3DV 2024. August 2023 I started a 14 week internship at Meta GenAI with Jialiang Wang in Menlo Park. June 2023 Check out our video presentation and demo video of Behind the Scenes. February 2023 Behind the Scenes was accepted at CVPR 2023. More updatesJanuary 2023 Pre-Print of new paper Behind the Scenes is online. April 2022 Started Ph.D. in Computer Vision at the chair of Daniel Cremers. March 2022 De-render3D was accepted at CVPR 2022. September 2021 Finished M.Sc. Computer Science at University of Oxford. March 2021 MonoRec was accepted at CVPR 2021. Check out our video and open-source code. October 2020 Started M.Sc. Computer Science at University of Oxford. October 2020 Finished ADL4CV. Check out our video presentation here. March 2020 Finished my B.Sc. Informatik at TUM. |
ResearchMy aim is to develop methods to understand the 3D world from images and videos. Specifically, I work on methods that can be trained with weak or even no supervision. Through this, I hope to enable more wide-spread applications of such methods, and to improve accuracy by training on large, unlabeled datasets. |
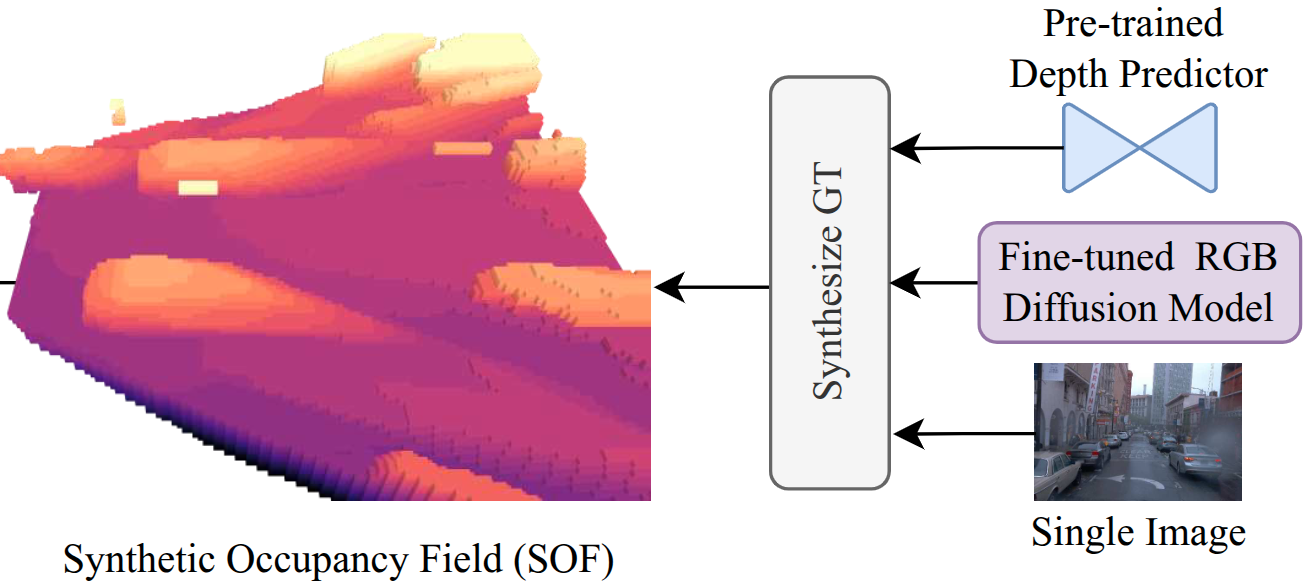
We leverage a diffusion model and a depth predictor to generate high-quality scene geometry from a single image. Then, we distill a feed-forward scene reconstruction model, which performs on par with reconstruction methods trained with multi-view supervision.
A method for consistent dynamic scene reconstruction via motion decoupling, bundle adjustment, and global refinement.
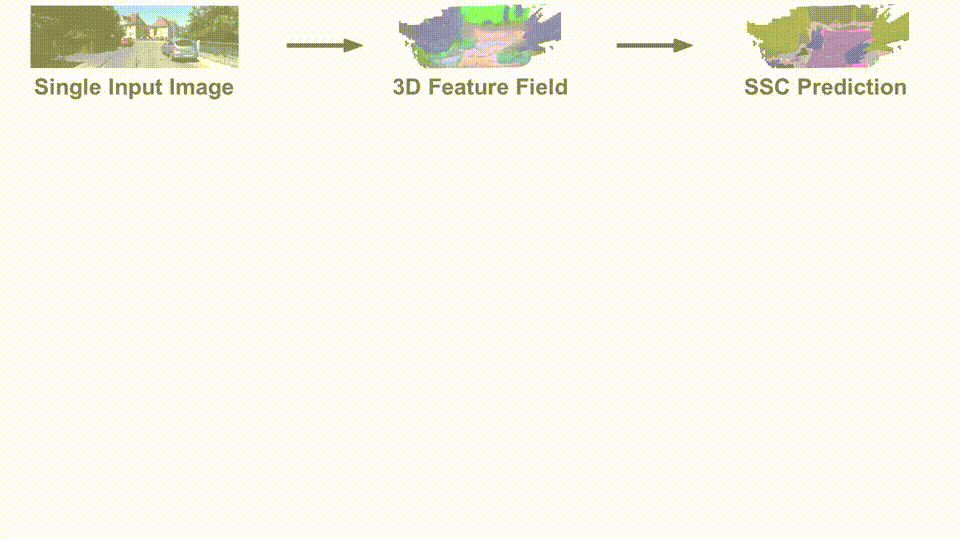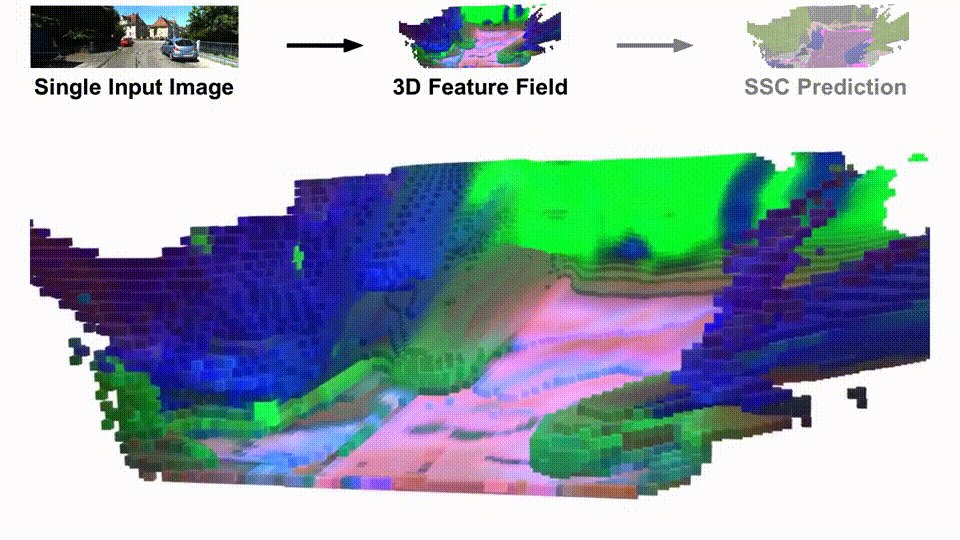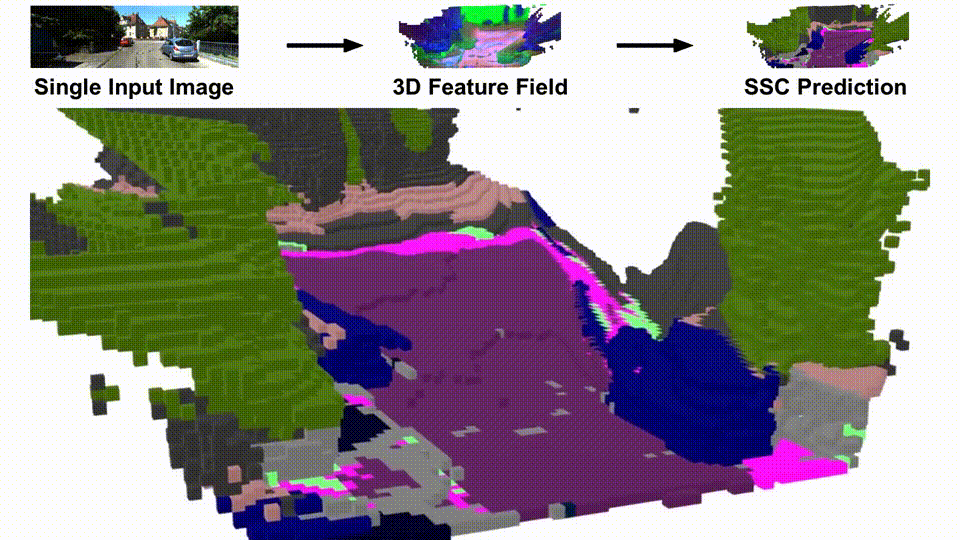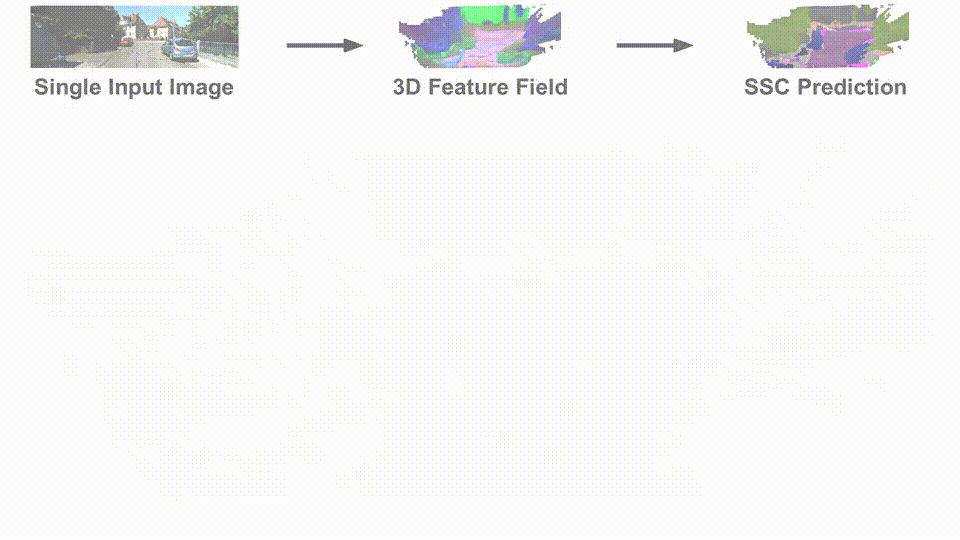
SceneDINO is unsupervised and infers 3D geometry and features from a single image in a feed-forward manner. Distilling and clustering SceneDINO's 3D feature field results in unsupervised semantic scene completion predictions. SceneDINO is trained using multi-view self-supervision.

A method for learning camera poses and intrinsics from dynamic casual videos.

We reuse layer computations from previous timesteps to make image generation with diffusion models more efficient.
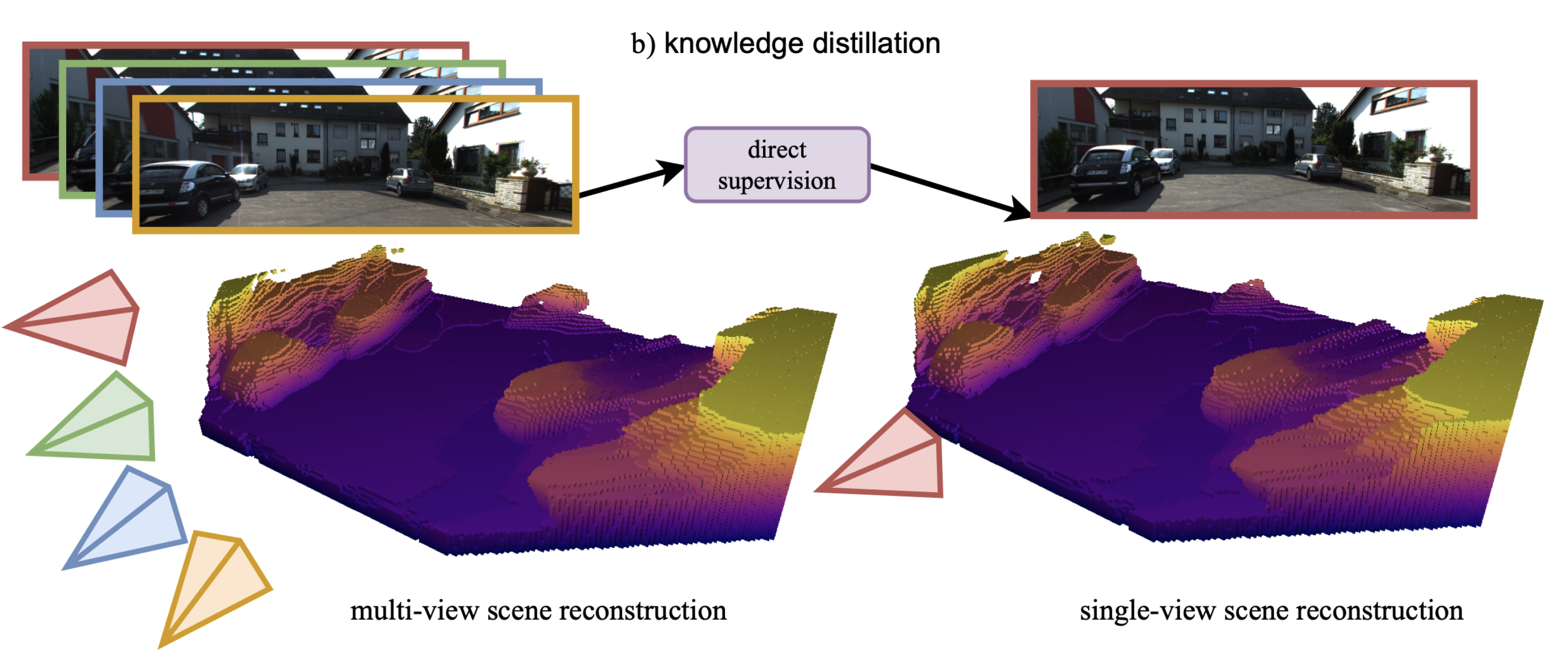
Leveraging multi-view supervision and distillation training to improve volumetric reconstruction from a single image.
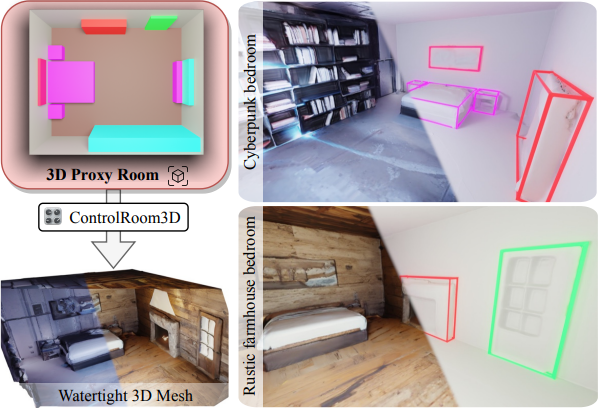
ControlRoom3D creates diverse and plausible 3D room meshes aligning well with user-defined room layouts and textual descriptions of the room style.

A self-supervised method for semantic scene completion, that rivals supervised approaches.

A self-supervised method for implicit volumetric reconstruction from a single image.

A self-supervised method for intrinsic image decomposition.

A state-of-the-art semi-supervised monocular dense reconstruction system, that utilizes a multi-view stereo approach with a filter for moving objects to predict depth maps in dynamic environments.